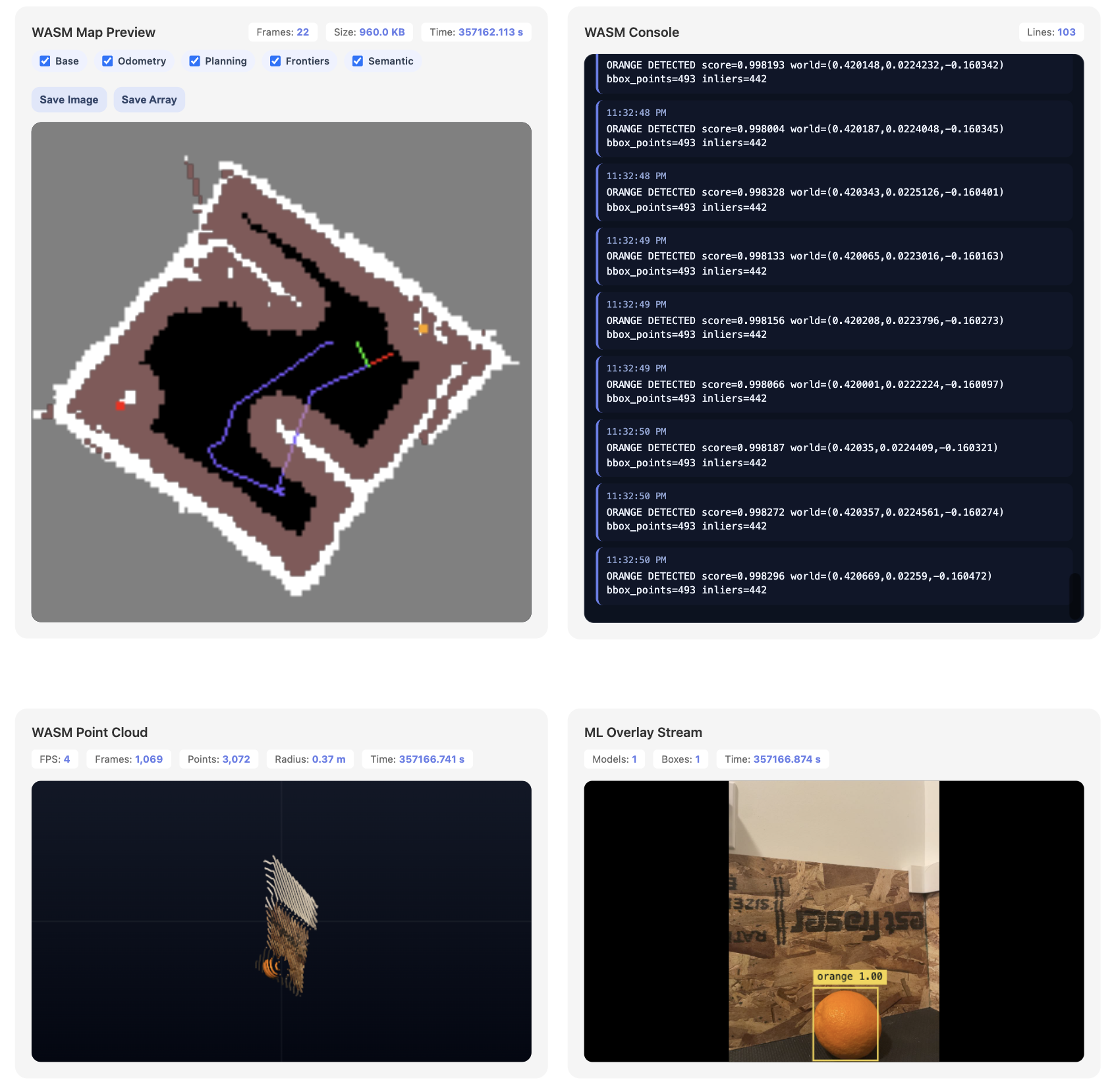
Semantic mapping demo
We have combined the detected ML bounding boxes to the mapping demo. Specifically, the model runs on camera frames; detected bounding boxes are corresponded to the LiDAR to get their spatial location. The points on the map corresponding to this location are then painted a special color to indicate their semantic class. To this end, we have also added a new “semantic” layer to the map visualization.
We chose to use fruits (apples and oranges) as the targets of choice. This is because they are invariant to viewing angle. Originally, we tried to use more driving-relevant obstacles such as stop signs and human cutouts; however, because they are flat, they can only be correctly identified at specific viewing angles. The model is not very large and accurate in the first place so this just seemed like adding too much difficulty to the problem.
Additional work still needs to be done to make this more robust: specifically, repeated observations need to be merged over time, producing more stable landmark estimates rather than frame-by-frame detections. The correspondence logic could also be improved; for example, the red apple in the image below is still missing the corresponding map point.